Convolutional Neural Networks (MyTorch ep.2)
CMU 11-785 Course: Deep Learning
In the MyTorch series (ep.1-3), I implemented my own deep learning library, a spinoff of PyTorch, from scratch: MLP, CNN, GRU, LSTM. In this assignment (ep.2), I implemented convolutional neural networks (CNN) from scratch.
Due to academic integrity policies, I would only go over broader concepts covered in this assignment, not the actual code. To demonstrate an CNN example, I would go over a simple traffic sign identification task using TensorFlow.
Convolutional Neural Networks —
CNNs learn and extract relevant features by applying a series of filters or convolutional layers to the input image. Each filter extracts a different feature or pattern from the image, such as edges, corners, or textures. It is also regarded as a position-invariant pattern detector that reduces parameter size in a deep neural network without losing too much in model quality. CNNs can be used for image classification, image recognition, object detection, image captioning, natural language processing, forecasting, and more.

Standard 2D CNN
Convolutional Layer —
This is the first layer which consists of many filters responsible for capturing different patterns. For example, if you have images of a house, this layer might extract the “door” patterns. Another filter might extract “window” patterns.
Resampling Layers (Upsampling and Downsampling) —
These are ways to make our input bigger or smaller. Downsampling is typically done to reduce the computation required in subsequent layers and to improve the model's ability to generalize to new data. Whereas, upsampling layers increase the spatial resolution of the feature maps by interpolating between the input pixels. This can be useful in tasks such as image segmentation, where it is necessary to produce a high-resolution output. This is where strides and padding become useful.

Activation —
We apply an activation function to the output of the convolutional layers in CNNs to introduce nonlinearity into the model. Without the activation function, the output of the convolutional layer would simply be a linear combination of the input pixels and the learned weights of the filter. Common activation functions used in CNNs include ReLU (Rectified Linear Unit), sigmoid, tanh, and softmax. ReLU is one of the most widely used because it is simple and computationally efficient, and has been shown to work well in practice. ReLU sets all negative values to zero, which effectively introduces sparsity into the model and reduces the number of parameters that need to be learned.
Pooling Layers —
These layers are used to reduce the dimensionality of the feature maps by aggregating the values in small regions of the map. Maxpooling takes the maximum value in each region, while meanpooling takes the average value.
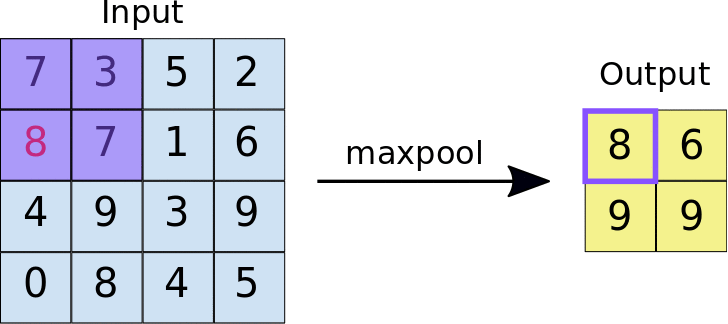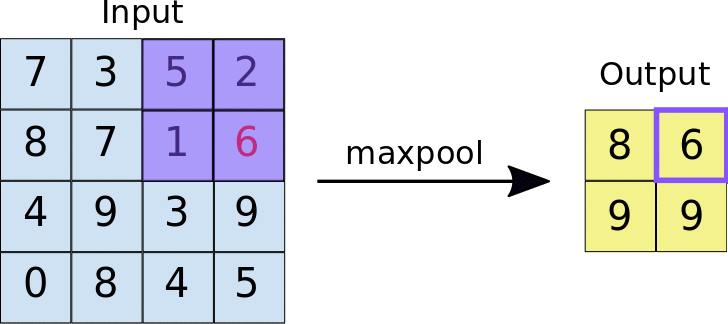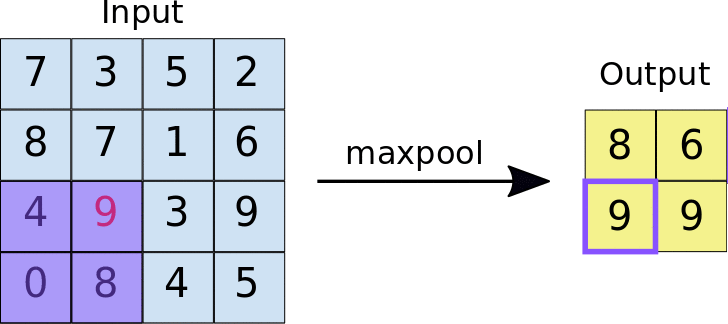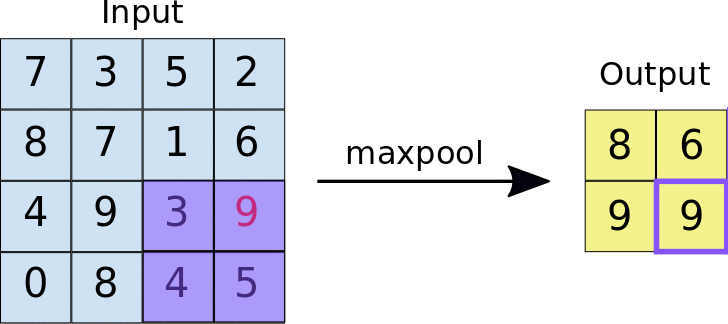
Flatten Layer —
This layer converts the output of the previous layer into a one-dimensional vector, which can then be passed through a fully connected layer for classification.
Classification Layer —
Once the relevant features have been extracted, and the output is flattened. It is passed through one or more fully connected layers, which perform the classification task. The output of the last fully connected layer is passed through a softmax activation function, which produces a probability distribution over the possible classes.
1D vs 2D CNNs —
1D CNNs are typically used for processing sequential data, such as time series or text data. In a 1D CNN, the input data is typically represented as a sequence of vectors, and the convolutional filters operate on the vector sequences along the time dimension.
2D CNNs are designed to process 2D data, such as images or spectrograms. In a 2D CNN, the input data is represented as a 2D matrix, and the convolutional filters operate on the matrix along both the spatial dimensions (height and width) and the channel dimension (color channels in images).

Conv1D

Conv2D
Example: CNN for Traffic Sign Identification

Here, I would go over a simple demonstration on the use of CNNs on a simple traffic sign identification task with the GTSRB - German Traffic Sign Recognition Benchmark (50000 images of 43 classes which are numbered from 0 to 42).
Reference: Develop your First Image Processing Project with Convolutional Neural Network!
Task—
Today self-driving cars are overtaking the automobile industry where drivers can fully depend on cars. To achieve high accuracy it’s important that cars should be able to understand all traffic rules. In this project, we are going to develop a traffic sign identification problem.
Steps —
install TensorFlow, Keras, Scikit-Learn, Pillow
download and load the traffic sign data into lists
split dataset into train and test
build the CNN model
Conv2D – convolutional layer
MaxPool2D – maximum pooling layer to reduce the size of images
Dropout – regularization technique to reduce overfitting
Flatten – squeeze the layers
Dense – for feed-forward neural network
compile the model
Loss Function – use categorical cross-entropy as this is a multi-class classification problem
Optimizer – to optimize the loss function
Metrics – calculate the accuracy
train for 15 epochs
plot the accuracy and loss graph
test the model
save the model for future use
# build the CNN model
model = tf.keras.Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation="relu", input_shape=x_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation="relu"))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))
model.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(rate=0.5))
model.add(Dense(43, activation="softmax"))
# compile the model
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# train for 15 epochs
history = model.fit(x_train, y_train, epochs=15, batch_size=64, validation_data=(x_test, y_test))



