Movie Streaming Recommendation Service
CMU 11-695 Course: AI Engineering / Machine Learning in Production
Objective —
The focus of this group project is to implement, evaluate, operate and monitor a movie streaming recommendation service in production, which entails many concerns, including deployment, scaling, reliability, drift and feedback loops. The streaming service has about 1 million customers and 27,000 movies (for comparison, Netflix has about 180 million subscribers and over 300 million estimated users worldwide and about 13,000 titles worldwide).
Data and Infrastructure—




This assignment consists of 4 main milestones with several deliverables. I briefly highlight a subset of the deliverables for each milestone below.
Milestone 1: Recommendation Model and First Deployment
Task —
Collect data from multiple sources and engineer features for learning
Apply state of the art machine learning tools
Deploy a model inference service
Measure and compare multiple quality attributes of your model
Practice teamwork and reflect on the process
Model comparisons: SVD vs KNN —
We chose Singular Value Decomposition (SVD) as one of our approaches both because it has a long record of being effective as the basis of a recommender system, and perhaps more importantly because it naturally allows us to directly estimate a rating given a user and item vector. This gives us a straightforward way of producing recommendations as we can calculate estimated ratings for a user and all potential movies and serve the movies that correspond to the top twenty estimated ratings. The K-Nearest Neighbors (KNN) model also adopts the idea of sparse matrix, however it differs in a sense that it incorporates the idea of 'similar users' into it. Just like SVM did, using the ratings data, KNN model first creates an MXN matrix of M users and N movies, each cell representing the ratings given by a particular user for a particular movie.
To decide which model we wanted to use one of the most important metrics was the prediction accuracy. It was possible to get RMSE for SVM, which measures the difference between the predicted and actual ratings of each movie. However, when it comes to the KNN model, we realized using RMSE as a performance metric may not be appropriate. Unlike SVM, KNN does not directly predict ratings for each movie. Instead, it searches for the nearest neighbors based on cosine similarity and then recommends items based on those similar users.

We decided to select the SVM model for deployment, mainly because it had a significant advantage in terms of inference time. Although KNN was better than SVM in terms of other measures (training cost, disk/memory size of the model), faster inference time is a crucial factor in model selection, especially when deploying the model in a production environment where real-time predictions are required. The faster inference time of the SVM model means that it can process more requests in a shorter amount of time, making it more suitable for deployment.
Milestone 2: Model and Infrastructure Quality
Task —
Test all components of the learning infrastructure
Build an infrastructure to assess model and data quality
Build an infrastructure to evaluate a model in production
Use continuous integration to test infrastructure and models
Offline Evaluation —
Offline evaluation is done with every run of our offline model pipeline command line tool which both trains and evaluates the model. Results are written directly to a log file in the specified log directory. One of the common pitfalls with a metric like RSME on large datasets is that this single number can hide bad performance for underrepresented subpopulations. To combat this, in our evaluation we use user attribute information to calculate RSME for each sex (Male and Female) and for 5 age demo groups (child, teen, young adult, middle aged, and senior).

Online Evaluation —
We compute this using a fraction of recommendations deemed successful; i.e. for which the user ended up watching any of the recommended movies within 15 minutes after receiving the recommendation.
Data Quality —
Some sources of issues with the data quality that we identified: invalid range of ratings values (i.e. 0-100) or data may suddenly have inconsistencies in how certain data points are recorded. We checked the rating values should be 1-5, movie recommendations should have 20 movies for each user, the kafka and response messages should follow the specific regex.
Pipeline —

A: We receive data about movies and users through an API and log files from past movie watching behavior through a Kafka stream.
B: Here, we cleaned and preprocessed the data from the API and Kafka stream by creating a schema and using regex and error handling for the schema.
C: Then, we extracted relevant features from the cleaned data
D: Using the extracted features, we trained our SVD model using the Surprise and Scikit-Learn libraries.
E: We evaluated the performance of the trained SVD model using the most recent ratings data as a hold out set. Here we tested thoroughly to ensure the the eval file is distinct from all train files used, and that the eval file was the most recent.
F: The trained SVM model was serialized to a file format that can be stored and loaded easily using the Python Pickle Library.
G: We served the serialized models as a REST API to make recommendations to the end-user. The prediction service is implemented using a simple Python Flask service which serves HTTP GET requests at http://<IP>:8082/recommend/<user\_id>. For consistency, the endpoint accesses the models through standardized interfaces.
H: To measure the performance and health of the pipeline, we collect and monitor the metric described in the Online Evaluation section using the existing stream dumper tool. This is the same tool that is also used in Step A. The evaluation is handled by a second script which analyzes the dumped telemetry data and produces another results dump and time series graph.
I: Visualisation of telemetry data and systems metrics will be handled in a future milestone.
Milestone 3: Monitoring and Continuous Deployment
Task —
Deploy a model prediction service with containers and support model updates without downtime
Build and operate a monitoring infrastructure for system health and model quality
Build an infrastructure for experimenting in production
Infrastructure for automatic periodic retraining of models
Version and track provenance of training data and models
Containerization —
All components of our system were containerized using Docker and deployed using docker-compose.
Monitoring —
Our monitoring infrastructure consists of Prometheus and Grafana. We define a Prometheus Gauge metric to track the service availability of the API. For live accuracy tracking we employ a PostgreSQL database with two tables, recommendations and zero_watch_minutes. From our Grafana dashboard, we then perform an SQL query which combines data from both tables to generate our live accuracy metric.

Service Availability

Model Accuracy
Milestone 4: Fairness, Security, and Feedback Loops
Task —
Reason about fairness requirements and their tradeoffs
Analyze the fairness of a system with concrete data
Identify feedback loops
Anticipate adversarial attacks and other security issues in machine-learning systems
Design and implement a monitoring strategy to detect feedback loops and attacks
Fairness Requirements —
The system should ensure that all data streams used to generate recommendations are representative of the diverse interests and preferences of its user base.
Biased or incomplete data streams can lead to inaccurate recommendations and exclusion of certain user groups, which can result in unfairness and decreased user satisfaction. To ensure fairness, the system should employ robust data collection methods that capture diverse perspectives and interests. A measure for assessing whether this requirement is met could be to conduct an analysis of the data streams used to generate recommendations and check whether they represent the interests and preferences of a diverse set of users.
The recommendation service should provide accurate and unbiased recommendations to all user groups regardless of their previous rankings or demographic information e.g. age, gender, or occupation.
This requirement is important because it ensures that users do not receive recommendations that are biased against them based on their previous preferences, rankings or demographic characteristics since, for example, we would be relying on user rankings in the training to predict new rankings and recommend movies to them. One measure to assess whether this requirement is met is to conduct an analysis of the recommendations provided to a diverse group of users with different demographic characteristics and previous rankings. The analysis could check whether the recommendations provided are similar in quality and accuracy across all groups.
Fairness Analysis —
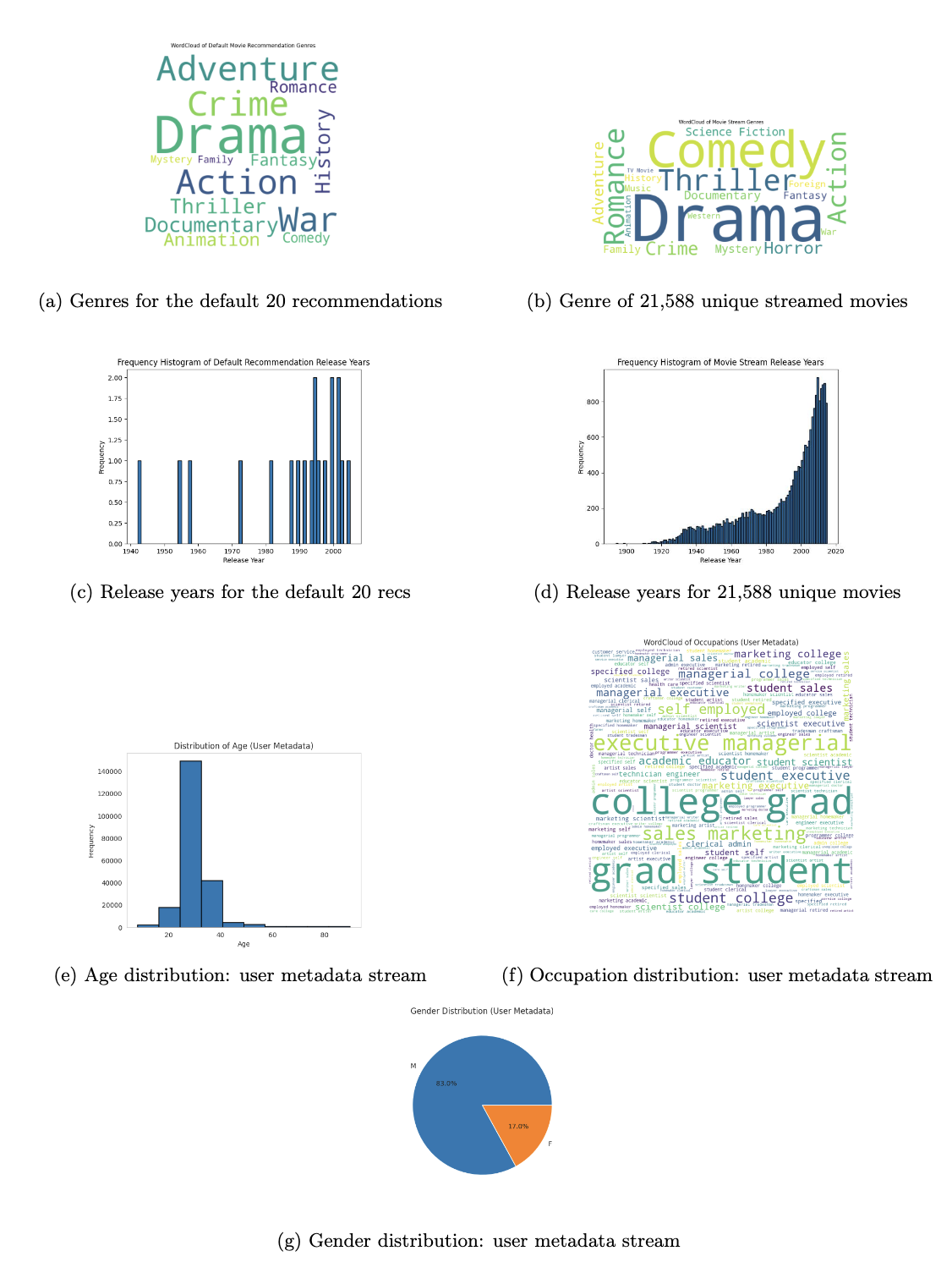
We chose to analyze the system fairness requirement, specifically focusing on the data coming from the stream. In order to assess if this requirement was met, we analyzed both the distribution of data coming from the stream and from our recommendations. For users who were not in our training dataset for our SVM model, we recommended them a list of 20 randomly chosen movies.
We extracted unique movie names and their watch minutes from an 8,332,861 data point stream, resulting in about 22,744 movies. Since the stream did not include movie genre metadata, we used an external MovieLens dataset with approximately 45,000 movies and their genres from Kaggle.
Our fairness requirement for the system is that the data streams are representative of a diverse user base. So, we also analyzed the user metadata for potential bias. We were also interested in knowing about the gender distribution of the users of our dataset.
Acknowledgement —
I would like to express my sincere gratitude to the professors (Prof. Eunsuk Kang and Prof. Christian Kaestner) for delivering the course content in an enjoyable, interactive, and memorable manner. This has been one of the most enjoyable classes I have taken. I also extend my appreciation to my exceptional teammates for their remarkable contribution to this project. Their talent, dedication, and collaboration made our team a success. At the end of the semester, we were thrilled to learn that our model was the top-performing model among the 30+ teams.



