Vision-Language Navigation with ALFRED
CMU 11-777 Course: MultiModal Machine Learning
ALFRED Dataset —
ALFRED includes 25,743 English language directives describing 8,055 expert demonstrations (with 3 or more language annotations each) averaging 50 steps each, resulting in 428,322 image-action pairs. A trajectory consists of a sequence of expert actions, the corresponding image observations, and language annotations describing segments of the trajectory. The default resolution of the RGB input is 300x300 but it is resized to 224 × 224 during training.
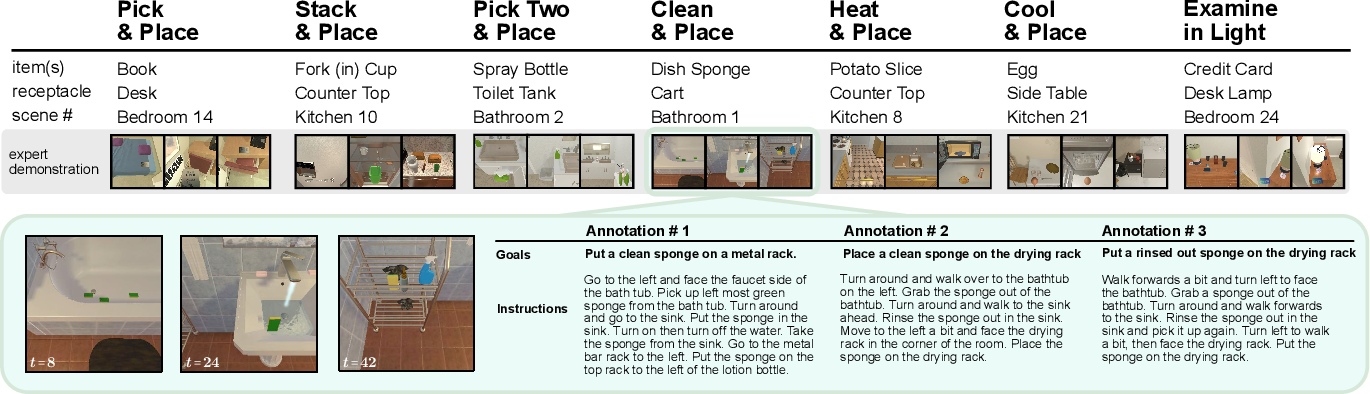
All 7 ALFRED tasks
Abstract —
The objective of this project is to develop a social agent that is capable of performing a wide range of tasks by accurately mapping human language instructions to actions, behaviors, and objects in interactive visual environments. To achieve this goal, we utilized the ALFRED benchmark dataset, which consists of tasks related to home automation and assistive robots for people with disabilities and the elderly.
Our proposed approach emphasizes the utilization of natural language and egocentric vision to train the model. This approach enables the model to handle situations where a single modality may be absent or unclear. The use of multiple modalities in training the agent is crucial in helping it attain a comprehensive understanding of its environment and perform diverse tasks. In addition, we propose a two-component architecture comprising a questioner and a performer to tackle the challenges in such tasks.
Inspired by the DialFRED architecture presented by Gao et al., 2022, the questioner component of our model is designed to actively ask questions while interacting with the environment to complete household tasks. The performer component is based on the E.T. model, a transformer-based architecture that encodes the full history of vision, language, and action inputs with a multimodal transformer.
The success of our model is attributed to the harmonious integration of various multimodal inputs, such as language, vision, instructions and more, similar to how humans perceive the world. We believe adding depth on top of RGB vision input has a potential to make the model more precise, as vision is the most crucial modality for such datasets.

Episodic Transformer Architecture
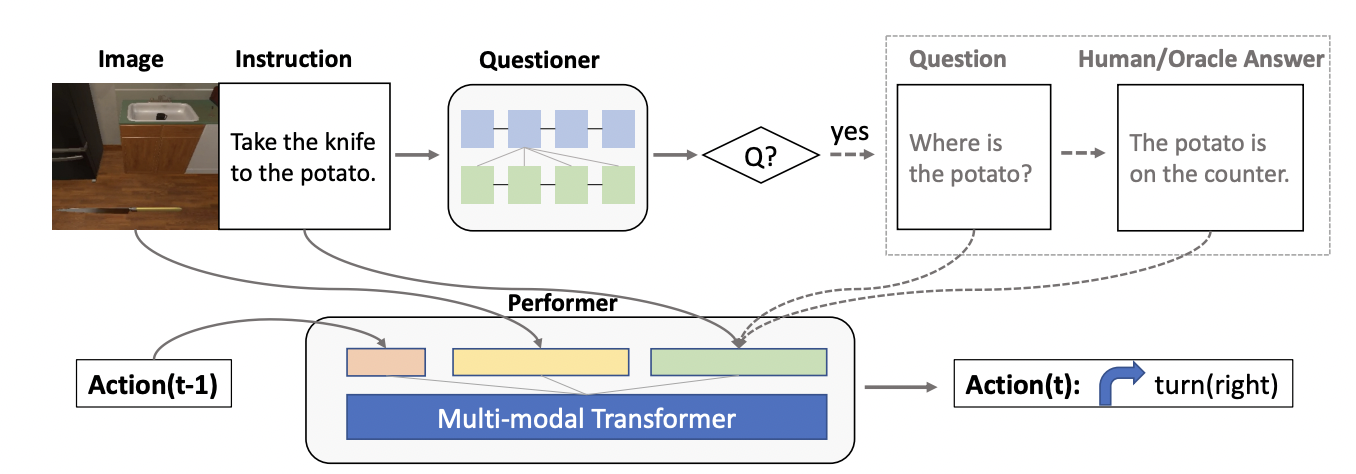
DIALFRED Architecture
Problem Definition —
Vision-Language Navigation (VLN) is a challenging task that involves mapping human language instructions to tasks that robots can perform, especially in real-world environments. The ALFRED dataset provides a benchmark for research in this area. One of the challenges in this task is navigating through real-world environments based on natural language instructions, which requires the harmonious integration of various sensory inputs such as language, vision, and touch.
Current methods have limitations in handling situations where a single modality may be absent or unclear, such as in a noisy environment. One of the states in which ALFRED agents fail is collision with objects. So, to narrow our research focus, we evaluate vision-language models on only the `pick and place' task to test their ability to perform motion and manipulation tasks based on natural language instructions.

Example of ALFRED task
This task is important because it tests the generalization ability of vision-language models in performing simple and complex manipulation tasks based on natural language instructions, such as picking up a mug from a coffee maker as seen in the figure below.
Reflection —
Working on this project was a complex task that required significant effort. One of the main challenges of working with the ALFRED dataset is the amount of time it takes to train models due to the large size of the dataset, which includes a vast collection of videos and instructions. Furthermore, running various baselines and evaluating the dataset of AI2THOR added to the complexity of the task. Despite these challenges, working with the ALFRED dataset was highly rewarding as it provided a valuable opportunity to learn about the challenges in this space and how to develop models that can better understand human language and interpret visual information.
Contribution —
I wrote the hypotheses about where cross modal interactions can be improved, researched papers that have worked on the ALFRED dataset and summarized their objectives. I wrote about the compute requirements for the ALFRED model and AI2THOR simulator. I also contributed to writing sections across the related datasets, unimodal baselines, prior work, and relevant techniques sections. For the baseline analysis, I worked on the No-Goal and No-Vision models and documented the baseline analysis insights in the report. To wrap up, I wrote the Ethical Concern section.
Acknowledgement —
I would like to acknowledge Professors Yonatan Bisk and Daniel Fried for their invaluable guidance, expertise, and insights with this course. I would also like to express my sincere gratitude to my research teammates who supported and collaborated with me throughout this project: Asmita Hajra, Rucha Kulkarni, Aishwarya Agrawal.